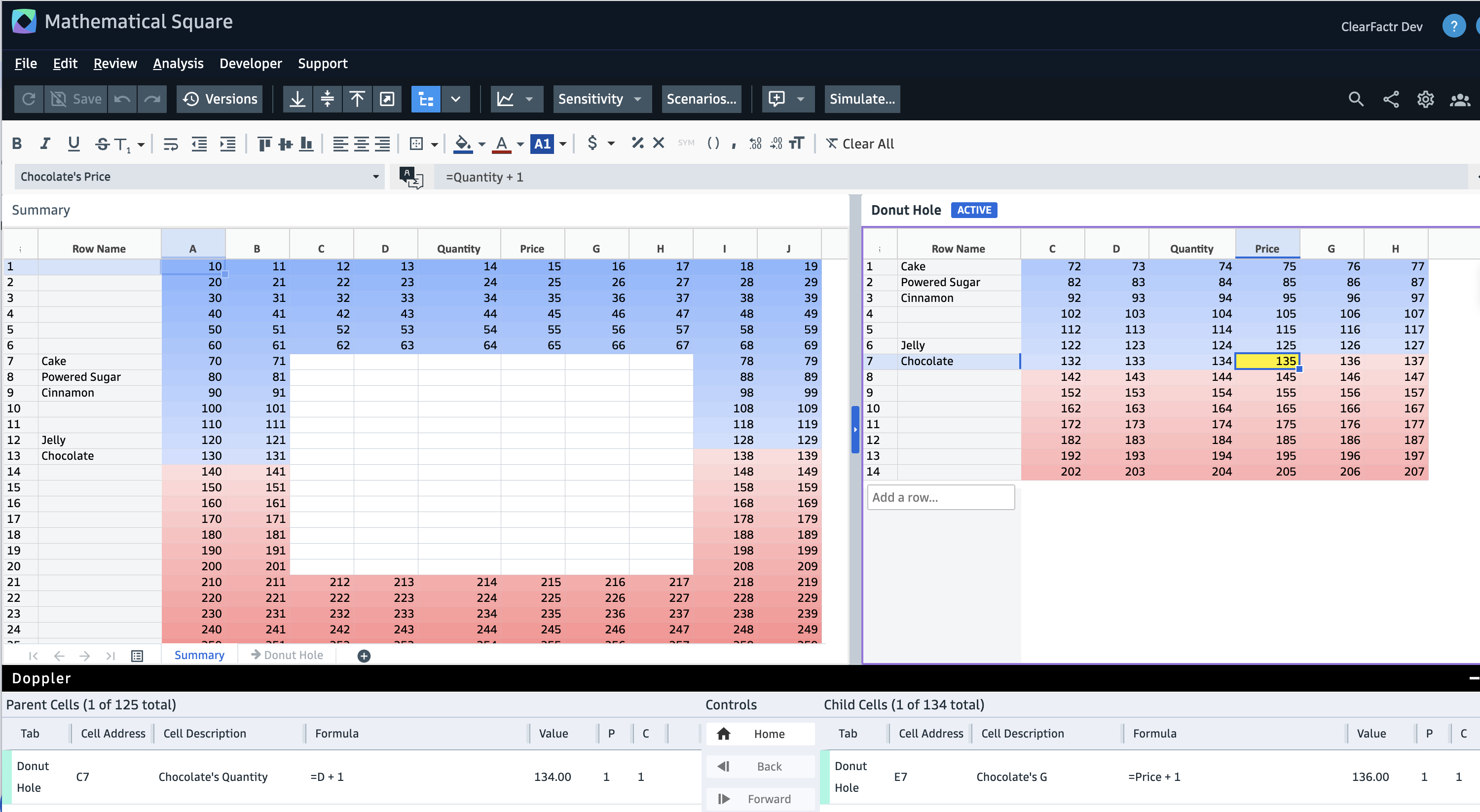
How we built ClearFactr's first end-user feature by prompting Claude Code inside IntelliJ — and why most of it already existed.

In prepping for the release of ClearFactr's MPC server, where you'll be able to create from scratch, edit, and compute with models using natural language prompts, I tripped up Claude Desktop on something. It's the kind of thing that might be impossible to find, or otherwise know about. Blog post worthy for sure!
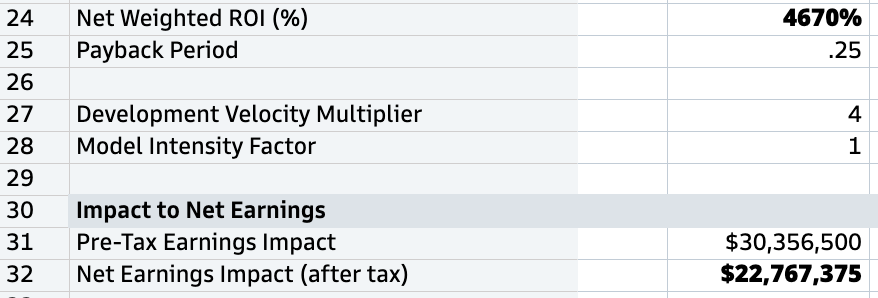
For those in the back: Four thousand, six hundred, and seventy percent.
That’s what Claude told me an enterprise ClearFactr customer might expect from using the platform at scale. It shocked even me. But there’s more...
This is post three of a series, important backstory here.
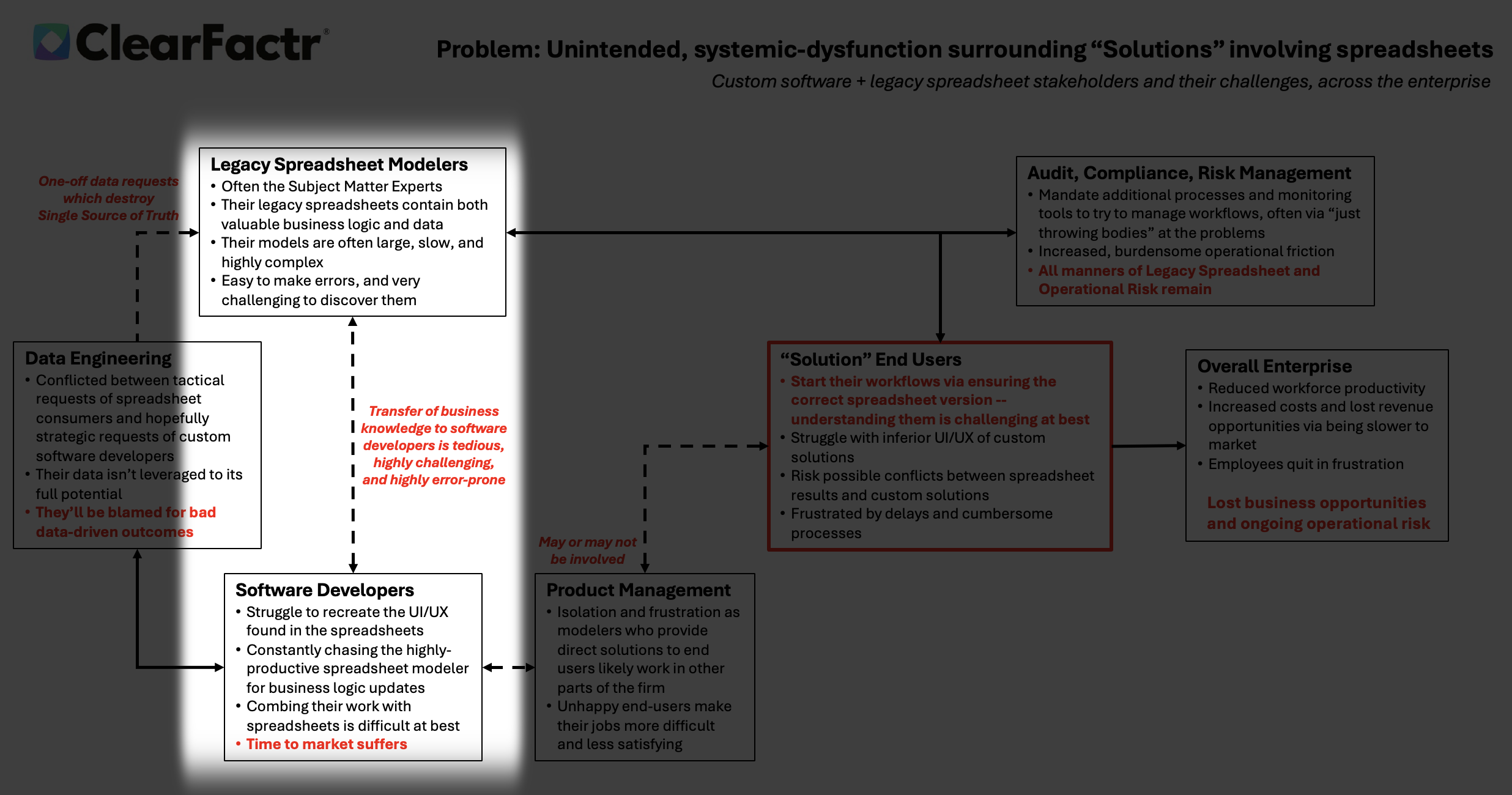
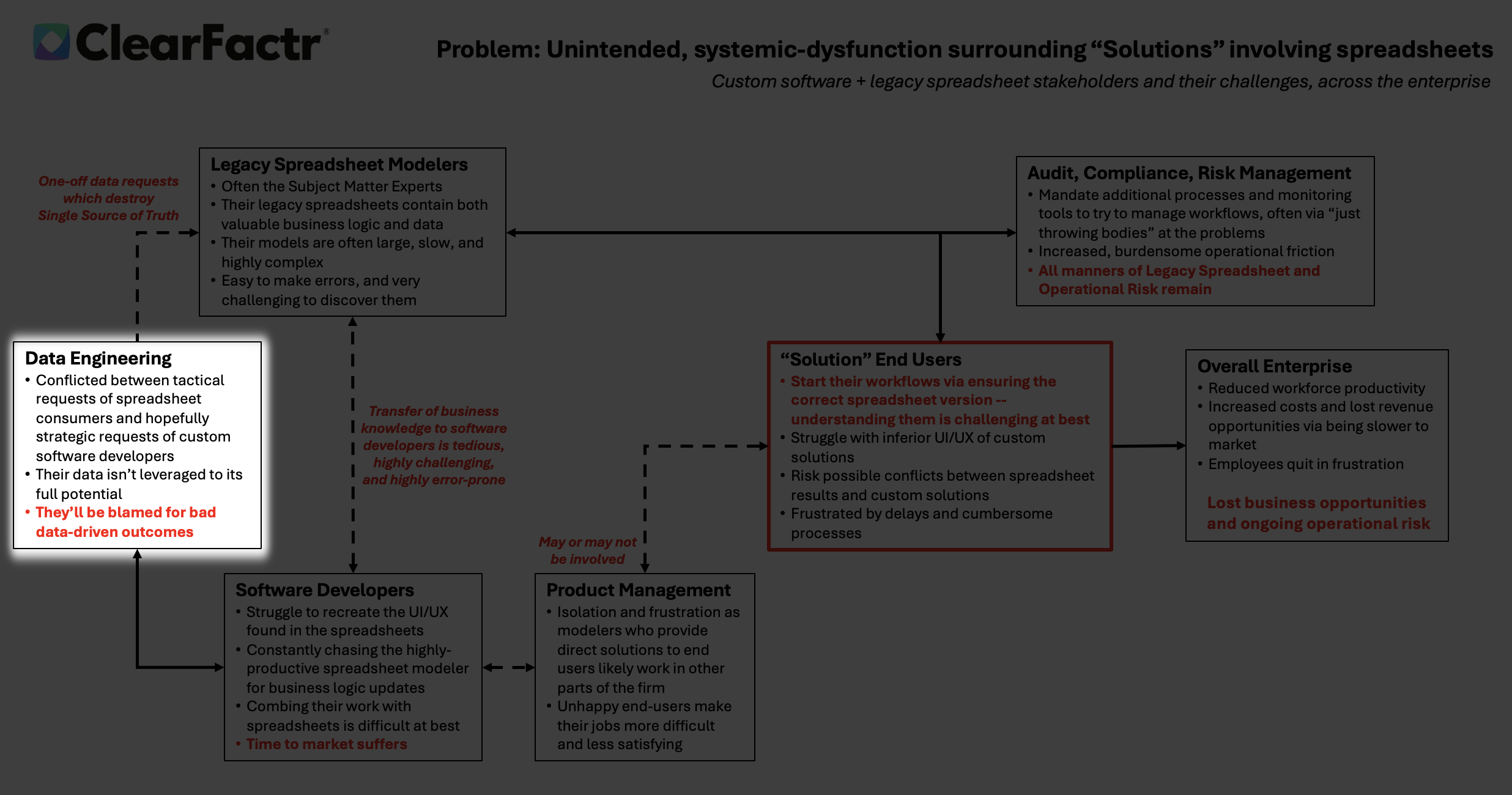
In the heart of many enterprises, a dotted line of friction divides two essential tribes: the Legacy Spreadsheet Modelers, often the unsung subject matter experts wielding Excel like a magic wand, and the Custom Software Developers, architects of scalable, structured systems. This connection, fragile and bidirectional, symbolizes a transfer of business knowledge that's tedious, error-prone, and riddled with misunderstandings. It's like handing off a novel written in hieroglyphs to someone who only reads binary.
This is post two of a series, important backstory here.
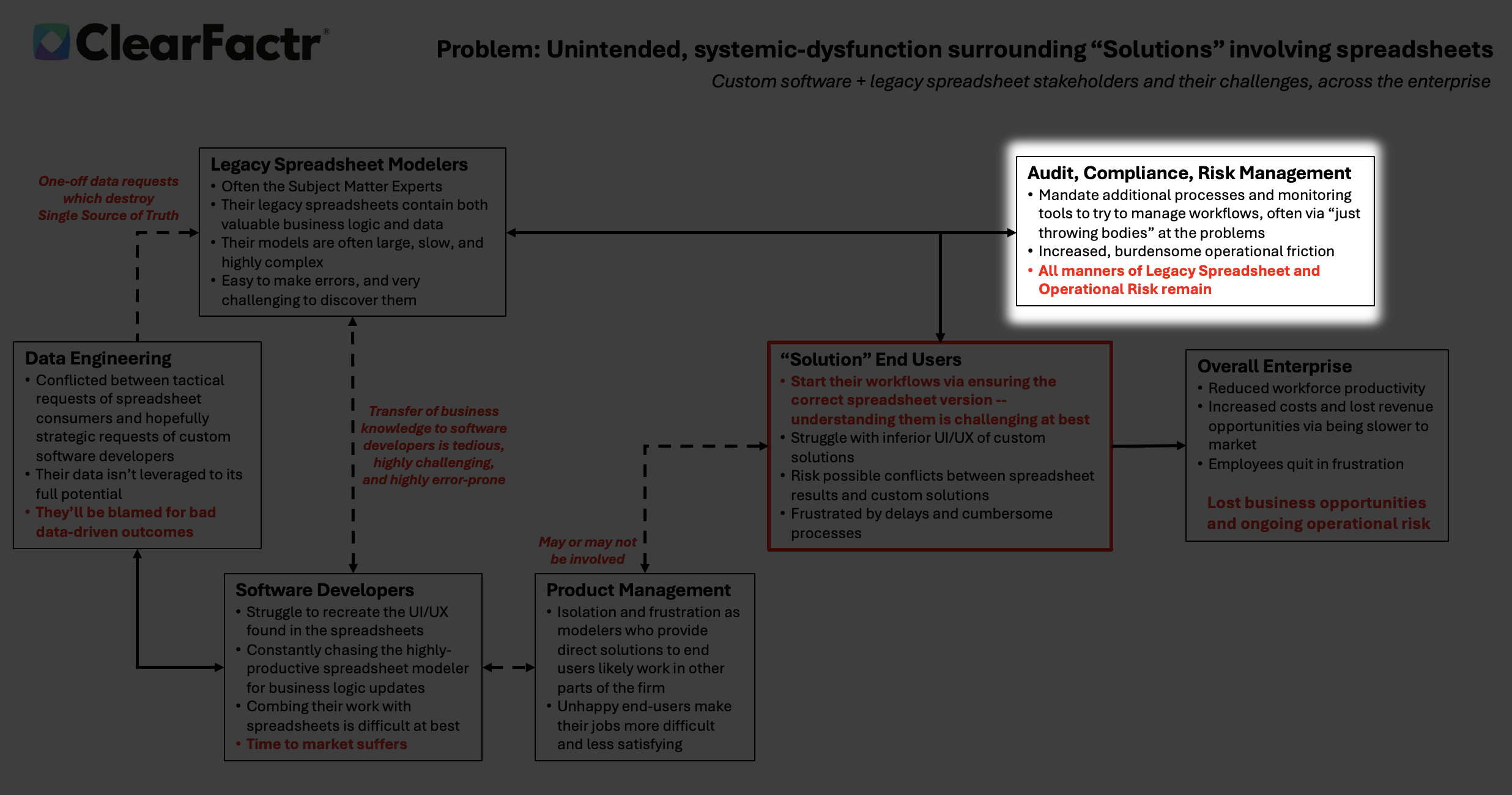
End-users live in perpetual doubt. Every morning (or meeting!) starts with the same ritual: “Is this the latest file? Did someone email a new version at 2 a.m.? Which tab has the real assumptions?”
This is post one of a series, important backstory here.
Data engineers are trapped in a vicious cycle: bombarded with urgent, one-off spreadsheet requests that fracture the single source of truth.
This post is a precursor to a series of posts, two of which are being released simultaneously. It's the necessary backstory to the series. Scroll to bottom for links to each related post.
Over a year ago I came up with two diagrams that describe what we typically see at the enterprise, before and after ClearFactr arrives. I personally feel I've never been able to improve upon their compactness and richness, and indeed, the themes of the two slides inform the totality of this website.