This is post one of a series, important backstory here.
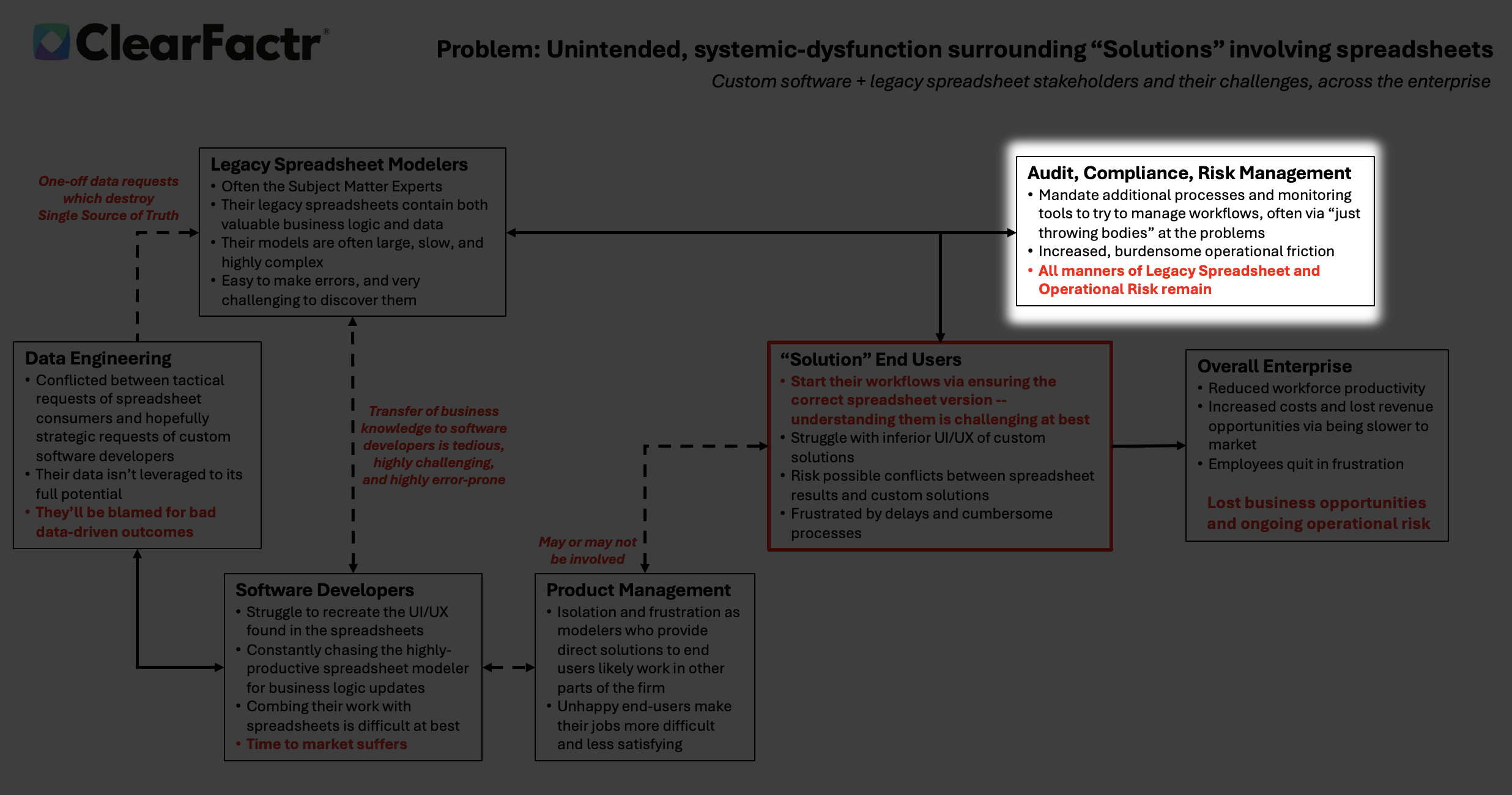
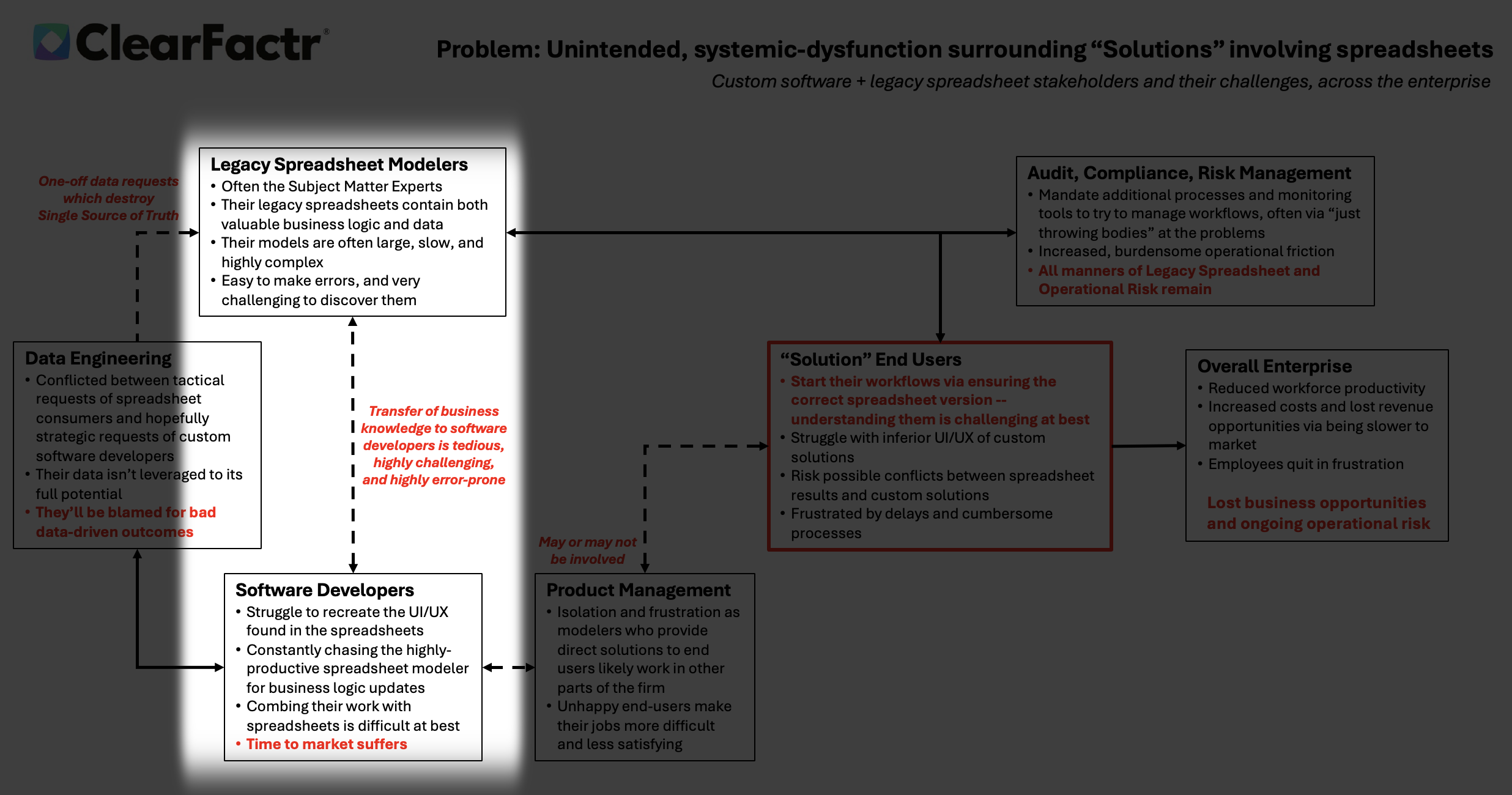
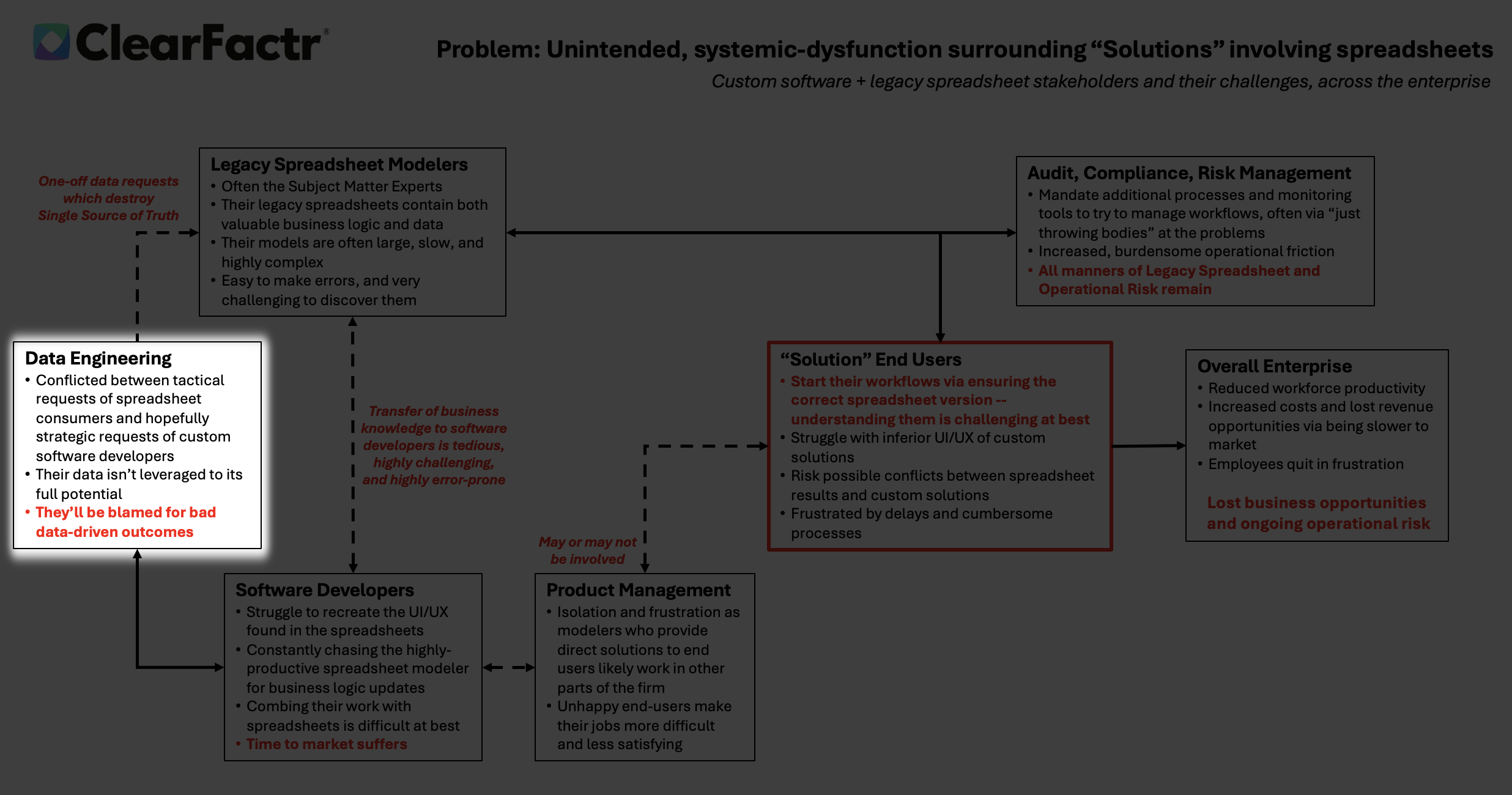
Data engineers are trapped in a vicious cycle: bombarded with urgent, one-off spreadsheet requests that fracture the single source of truth.
Every tactical pull duplicates data, undermines governance, and starves strategic initiatives. They’re forced to prioritize firefighting over architecture—leaving datasets under-leveraged, AI training starved, and themselves perpetually blamed when flawed models produce garbage outcomes.
End-users bear the fallout. Their workflows start with a chaotic hunt for the “right” spreadsheet version, and inevitably wind up via deciphering opaque logic buried in someone else’s masterpiece. Custom solutions arrive late, if at all, with clunky interfaces that pale against the spreadsheet’s familiar (if flawed) flexibility. Conflicting results between systems breed distrust; delays erode confidence. They’re stuck cross-verifying outputs, second-guessing decisions, and navigating processes often bloated by audit overreach.
The disconnect is brutal: data engineers can’t scale trust, end-users can’t scale speed. Productivity tanks, risk compounds, and frustration festers, all because critical data remains locked in brittle, ungoverned workbooks.
No one wins when the bridge between data and decisions is built on sand.
Sound familiar?
Yes, there's more to this picture! Here it is.
And how does ClearFactr solve this? Here are some of the ways:
https://www.clearfactr.com/separate-data-and-compute
https://www.clearfactr.com/partners/databricks